Processing a header and trailer textfile in Datastage
Example case
The input file in our scenario is a stream of records representing invoices. It is a text file in a header-trailer format and has the following structure:- A header starts with a letter H which is followed by an invoice number, a customer number, a date and invoice currency - Every item starts with a letter I which is followed by product ID, product age, quantity and net value - And the trailer starts with a T and contains two values which fullfill the role of a checksum: the total number of invoice lines and total net value.
Header and trailer input textfile in Datastage:
Solution
Datastage job design which solves the problem of loading an extract structured into headers and items:
Detailed illustration of each component of the job
trsfGetKinds transformer - a type of record is extracted from each input line and assigned and written into a kind column
The transformer reads first character of each line to mark records and divide them into kinds:
trsfAssignHeaders transformer assigns invoice headers to each line of the input flow. Invoice header is a 8 character key which is extracted from the dataline using the following formula: L02.data_line[1,8]
A datastage transformer which assigns headers using a stage variable:
trsfReformat transformer splits the data flow into invoice headers and invoice lines. A InvoiceLineID stage variable is used to populate a sequence number for each invoice line. In order to correctly load net value, the ereplace function replaces commas with dots in this numeric field.
The following transformer splits the flow into headers and items and reformats records into a corresponding structure:
Target oracle tables with correctly loaded invoice headers and lines:
Sunday, June 27, 2010
Datastage server job designs
Datastage server job designs
Examples of datastage server job designs which are solutions for real problems in the data warehouse environment.
Design of a DataStage server job with Oracle plsql procedure call
Example of a DataStage server aggregation job with use of containters
Datastage sequences examples
Design of a Datastage job sequence with email notification
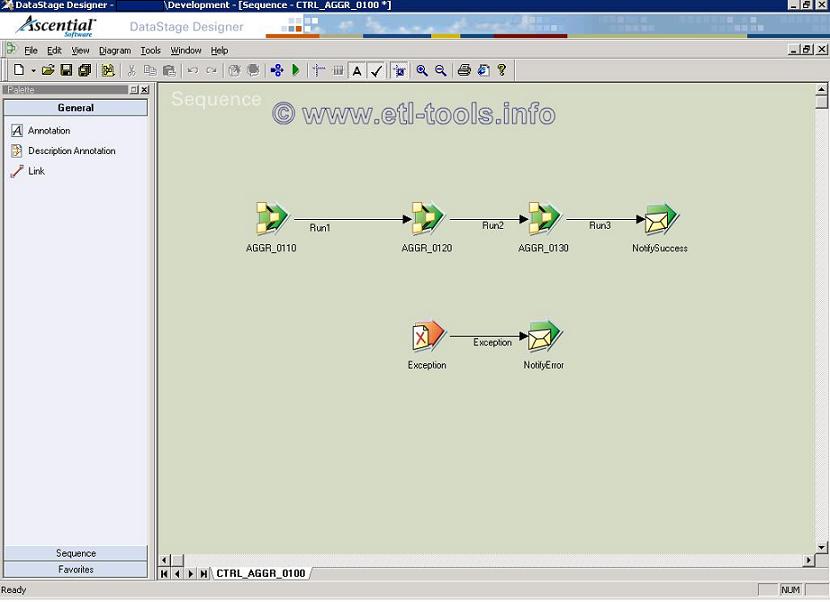
Design of a complex Datastage server job sequence with parallel job execution
Examples of datastage server job designs which are solutions for real problems in the data warehouse environment.
Design of a DataStage server job with Oracle plsql procedure call
Example of a DataStage server aggregation job with use of containters
Datastage sequences examples
Design of a Datastage job sequence with email notification
Design of a complex Datastage server job sequence with parallel job execution
SCD Type 3,4
SCD Type 3
In the Type 3 Slowly Changing Dimension only the information about a previous value of a dimension is written into the database. An 'old 'or 'previous' column is created which stores the immediate previous attribute. In Type 3 SCD users are able to describe history immediately and can report both forward and backward from the change. However, that model can't track all historical changes, such as when a dimension changes twice or more. It would require creating next columns to store historical data and could make the whole data warehouse schema very complex. To implement SCD Type 3 in Datastage use the same processing as in the SCD-2 example, only changing the destination stages to update the old value with a new one and update the previous value field.
SCD Type 4
The Type 4 SCD idea is to store all historical changes in a separate historical data table for each of the dimensions. To implement SCD Type 4 in Datastage use the same processing as in the SCD-2 example, only changing the destination stages to insert an old value into the destionation stage connected to the historical data table (D_CUSTOMER_HIST for example) and update the old value with a new one.
In the Type 3 Slowly Changing Dimension only the information about a previous value of a dimension is written into the database. An 'old 'or 'previous' column is created which stores the immediate previous attribute. In Type 3 SCD users are able to describe history immediately and can report both forward and backward from the change. However, that model can't track all historical changes, such as when a dimension changes twice or more. It would require creating next columns to store historical data and could make the whole data warehouse schema very complex. To implement SCD Type 3 in Datastage use the same processing as in the SCD-2 example, only changing the destination stages to update the old value with a new one and update the previous value field.
SCD Type 4
The Type 4 SCD idea is to store all historical changes in a separate historical data table for each of the dimensions. To implement SCD Type 4 in Datastage use the same processing as in the SCD-2 example, only changing the destination stages to insert an old value into the destionation stage connected to the historical data table (D_CUSTOMER_HIST for example) and update the old value with a new one.
SCD Type 2
SCD Type 2
Slowly changing dimension Type 2 is a model where the whole history is stored in the database. An additional dimension record is created and the segmenting between the old record values and the new (current) value is easy to extract and the history is clear. The fields 'effective date' and 'current indicator' are very often used in that dimension and the fact table usually stores dimension key and version number.
SCD 2 implementation in Datastage
The job described and depicted below shows how to implement SCD Type 2 in Datastage. It is one of many possible designs which can implement this dimension.For this example, we will use a table with customers data (it's name is D_CUSTOMER_SCD2) which has the following structure and data:
D_CUSTOMER dimension table before loading
CUST_ID
CUST_NAME
CUST_GROUP_ID
CUST_TYPE_ID
CUST_COUNTRY_ID
REC_VERSION
REC_EFFDT
REC_CURRENT_IND
DRBOUA7
Dream Basket
EL
S
PL
1
2006-10-01
Y
ETIMAA5
ETL tools info
BI
C
FI
1
2006-09-29
Y
FAMMFA0
Fajatso
FD
S
CD
1
2006-09-27
Y
FICILA0
First Pactonic
FD
C
IT
1
2006-09-25
Y
FRDXXA2
Frasir
EL
C
SK
1
2006-09-23
Y
GAMOPA9
Ganpa LTD.
FD
C
US
1
2006-09-21
Y
GGMOPA9
GG electronics
EL
S
RU
1
2006-09-19
Y
GLMFIA6
Glasithklini
FD
S
PL
1
2006-09-17
Y
GLMPEA9
Globiteleco
TC
S
FI
1
2006-09-15
Y
GONDWA5
Goli Airlines
BN
S
GB
1
2006-09-13
Y
Datastage SCD2 job designThe most important facts and stages of the CUST_SCD2 job processing:
The dimension table with customers is refreshed daily and one of the data sources is a text file. For the purpose of this example the CUST_ID=ETIMAA5 differs from the one stored in the database and it is the only record with changed data. It has the following structure and data:
SCD 2 - Customers file extract:
There is a hashed file (Hash_NewCust) which handles a lookup of the new data coming from the text file.
A T001_Lookups transformer does a lookup into a hashed file and maps new and old values to separate columns.
SCD 2 lookup transformer
A T002_Check_Discrepacies_exist transformer compares old and new values of records and passes through only records that differ.
SCD 2 check discrepancies transformer
A T003 transformer handles the UPDATE and INSERT actions of a record. The old record is updated with current indictator flag set to no and the new record is inserted with current indictator flag set to yes, increased record version by 1 and the current date.
SCD 2 insert-update record transformer
ODBC Update stage (O_DW_Customers_SCD2_Upd) - update action 'Update existing rows only' and the selected key columns are CUST_ID and REC_VERSION so they will appear in the constructed where part of an SQL statement.
ODBC Insert stage (O_DW_Customers_SCD2_Ins) - insert action 'insert rows without clearing' and the key column is CUST_ID.
Slowly changing dimension Type 2 is a model where the whole history is stored in the database. An additional dimension record is created and the segmenting between the old record values and the new (current) value is easy to extract and the history is clear. The fields 'effective date' and 'current indicator' are very often used in that dimension and the fact table usually stores dimension key and version number.
SCD 2 implementation in Datastage
The job described and depicted below shows how to implement SCD Type 2 in Datastage. It is one of many possible designs which can implement this dimension.For this example, we will use a table with customers data (it's name is D_CUSTOMER_SCD2) which has the following structure and data:
D_CUSTOMER dimension table before loading
CUST_ID
CUST_NAME
CUST_GROUP_ID
CUST_TYPE_ID
CUST_COUNTRY_ID
REC_VERSION
REC_EFFDT
REC_CURRENT_IND
DRBOUA7
Dream Basket
EL
S
PL
1
2006-10-01
Y
ETIMAA5
ETL tools info
BI
C
FI
1
2006-09-29
Y
FAMMFA0
Fajatso
FD
S
CD
1
2006-09-27
Y
FICILA0
First Pactonic
FD
C
IT
1
2006-09-25
Y
FRDXXA2
Frasir
EL
C
SK
1
2006-09-23
Y
GAMOPA9
Ganpa LTD.
FD
C
US
1
2006-09-21
Y
GGMOPA9
GG electronics
EL
S
RU
1
2006-09-19
Y
GLMFIA6
Glasithklini
FD
S
PL
1
2006-09-17
Y
GLMPEA9
Globiteleco
TC
S
FI
1
2006-09-15
Y
GONDWA5
Goli Airlines
BN
S
GB
1
2006-09-13
Y
Datastage SCD2 job designThe most important facts and stages of the CUST_SCD2 job processing:
The dimension table with customers is refreshed daily and one of the data sources is a text file. For the purpose of this example the CUST_ID=ETIMAA5 differs from the one stored in the database and it is the only record with changed data. It has the following structure and data:
SCD 2 - Customers file extract:
There is a hashed file (Hash_NewCust) which handles a lookup of the new data coming from the text file.
A T001_Lookups transformer does a lookup into a hashed file and maps new and old values to separate columns.
SCD 2 lookup transformer
A T002_Check_Discrepacies_exist transformer compares old and new values of records and passes through only records that differ.
SCD 2 check discrepancies transformer
A T003 transformer handles the UPDATE and INSERT actions of a record. The old record is updated with current indictator flag set to no and the new record is inserted with current indictator flag set to yes, increased record version by 1 and the current date.
SCD 2 insert-update record transformer
ODBC Update stage (O_DW_Customers_SCD2_Upd) - update action 'Update existing rows only' and the selected key columns are CUST_ID and REC_VERSION so they will appear in the constructed where part of an SQL statement.
ODBC Insert stage (O_DW_Customers_SCD2_Ins) - insert action 'insert rows without clearing' and the key column is CUST_ID.
SCD Type 1
SCD Type 1
Type 1 Slowly Changing Dimension data warehouse architecture applies when no history is kept in the database. The new, changed data simply overwrites old entries. This approach is used quite often with data which change over the time and it is caused by correcting data quality errors (misspells, data consolidations, trimming spaces, language specific characters).Type 1 SCD is easy to maintain and used mainly when losing the ability to track the old history is not an issue.
SCD 1 implementation in Datastage
The job described and depicted below shows how to implement SCD Type 1 in Datastage. It is one of many possible designs which can implement this dimension. The example is based on the customers load into a data warehouse
Datastage SCD1 job designThe most important facts and stages of the CUST_SCD2 job processing:
There is a hashed file (Hash_NewCust) which handles a lookup of the new data coming from the text file.
A T001_Lookups transformer does a lookup into a hashed file and maps new and old values to separate columns.
SCD1 Transformer mapping
A T002 transformer updates old values with new ones without concerning about the overwritten data.
SCD1 Transformer update old entries
The database is updated in a target ODBC stage (with the 'update existing rows' update action)
Type 1 Slowly Changing Dimension data warehouse architecture applies when no history is kept in the database. The new, changed data simply overwrites old entries. This approach is used quite often with data which change over the time and it is caused by correcting data quality errors (misspells, data consolidations, trimming spaces, language specific characters).Type 1 SCD is easy to maintain and used mainly when losing the ability to track the old history is not an issue.
SCD 1 implementation in Datastage
The job described and depicted below shows how to implement SCD Type 1 in Datastage. It is one of many possible designs which can implement this dimension. The example is based on the customers load into a data warehouse
Datastage SCD1 job designThe most important facts and stages of the CUST_SCD2 job processing:
There is a hashed file (Hash_NewCust) which handles a lookup of the new data coming from the text file.
A T001_Lookups transformer does a lookup into a hashed file and maps new and old values to separate columns.
SCD1 Transformer mapping
A T002 transformer updates old values with new ones without concerning about the overwritten data.
SCD1 Transformer update old entries
The database is updated in a target ODBC stage (with the 'update existing rows' update action)
ETL process
Implementing ETL process in Datastage to load the DataWarehouse
ETL process
From an ETL definition the process involves the three tasks:
extract data from an operational source or archive systems which are the primary source of data for the data warehouse.
transform the data - which may involve cleaning, filtering and applying various business rules
load the data into a data warehouse or any other database or application that houses data
ETL process from a Datastage standpoint
In datastage the ETL execution flow is managed by controlling jobs, called Job Sequences. A master controlling job provides a single interface to pass parameter values down to controlled jobs and launch hundreds of jobs with desired parameters. Changing runtime options (like moving project from testing to production environment) is done in job sequences and does not require changing the 'child' jobs. Controlled jobs can be run in parallel or in serial (when a second job is dependant on the first). In case of serial job execution it's very important to check if the preceding set of jobs was executed successfully. A normal datastage ETL process can be broken up into the following segments (each of the segments can be realized by a set of datastage jobs):
jobs accessing source systems - extract data from the source systems. They typically do some data filtering and validations like trimming white spaces, eliminating (replacing) nulls, filtering irrelevant data (also sometimes detect if the data has changed since the last run by reading timestamps).
loading lookups - these jobs usually need to be run in order to run transformations. They load lookup hashed files, prepare surrogate key mapping files, set up data sequences and set up some parameters.
transformations jobs - these are jobs where most of the real processing is done. They apply business rules and shape the data that would be loaded into the data warehouse (dimension and fact tables).
loading jobs load the transformed data into the database. Usually a typical Data Warehouse load involves assigning surrogate keys, loading dimension tables and loading fact tables (in a Star Schema example).
Datawarehouse master load sequence
Usually the whole set of daily executed datastage jobs is run and monitored by one Sequence job. It's created graphically in datastage designer in a similiar way as a normal server job. Very often the following job sequencer stages/activities are used to do a master controller:
Wait for file activity - check for a file which would trigger the whole processing
Execute command - executes operating system commands or datastage commands
Notification - sends email with a notification and/or job execution log. Can also be invoked when an exception occurs and for example notify people from support so they are aware of a problem straight away
Exception - catches exceptions and can be combined with notification stage
Example of a master job sequence architecture
It's a good practice to follow one common naming convention of jobs. Job names proposed in the example are clear, easy to sort and to analyze what's the jobs hierarchy. -Master job controller: SEQ_1000_MAS --Job sequences accessing source: SEQ_1100_SRC ----loading customers: SEQ_1110_CUS ----loading products: SEQ_1120_PRD ----loading time scale: SEQ_1130_TM ----loading orders: SEQ_1140_ORD ----loading invoices: SEQ_1150_INV --Job filling up lookup keys : SEQ_1200_LK ----loading lookups: SEQ_1210_LK --Job sequences for transforming data: SEQ_1300_TRS ----transforming customers (dimension): SEQ_1310_CUS_D ----transforming products (dimension): SEQ_1320_PRD_D ----transforming time scale (dimension): SEQ_1330_TM_D ----transforming orders (fact): SEQ_1340_ORD_F ----transforming invoices (fact): SEQ_1350_INV_F --Job sequence for loading the transformed data into the DW: SEQ_1400_LD The master job controller (sequence job) for data warehouse load process SEQ_1000_MAS can be designed as depicted below. Please notice that it will not start until a trigger file is present (WaitFoRFile activity). The extract-transform-load job sequences (each of them may contain server jobs or job sequences) will be triggered in serial fashion (not in paralell) and an email notification will finish the process.
Mater job sequence for loading a DataWarehouse
Designing jobs - looking up data using hash files
Designing jobs - looking up data using hash files
The data in Datastage can be looked up from a hashed file or from a database (ODBC/ORACLE) source. Lookups are always managed by the transformer stage.A Hashed File is a reference table based on key fields which provides fast access for lookups. They are very useful as a temporary or non-volatile program storage area. An advantage of using hashed files is that they can be filled up with remote data locally for better performance. To increase performance, hashed files can be preloaded into memory for fast reads and support write-caching for fast writes. There are also situations where loading a hashed file and using it for lookups is much more time consuming than accessing directly a database table. It usually happens where there is a need to access more complex data than a simple key-value mapping, for example what the data comes from multiple tables, must be grouped or processed in a database specific way. In that case it's worth considering using ODBC or Oracle stage.
Please refer to the examples below to find out what is the use of lookups in Datastage
In the transformer depicted below there is a lookup into a country dictionary hash file. If a country is matched it is written to the right-hand side column, if not - a "not found" string is generated.
Design of a datastage transformer with lookup
In the job depicted below there is a sequential file lookup, linked together with a hash file which stores the temporary data.
The data in Datastage can be looked up from a hashed file or from a database (ODBC/ORACLE) source. Lookups are always managed by the transformer stage.A Hashed File is a reference table based on key fields which provides fast access for lookups. They are very useful as a temporary or non-volatile program storage area. An advantage of using hashed files is that they can be filled up with remote data locally for better performance. To increase performance, hashed files can be preloaded into memory for fast reads and support write-caching for fast writes. There are also situations where loading a hashed file and using it for lookups is much more time consuming than accessing directly a database table. It usually happens where there is a need to access more complex data than a simple key-value mapping, for example what the data comes from multiple tables, must be grouped or processed in a database specific way. In that case it's worth considering using ODBC or Oracle stage.
Please refer to the examples below to find out what is the use of lookups in Datastage
In the transformer depicted below there is a lookup into a country dictionary hash file. If a country is matched it is written to the right-hand side column, if not - a "not found" string is generated.
Design of a datastage transformer with lookup
In the job depicted below there is a sequential file lookup, linked together with a hash file which stores the temporary data.
Designing jobs - tranforming and filtering data
Designing jobs - tranforming and filtering data
It's a very common situation and a good practice to design datastage jobs in which data flow goes in the following way: EXTRACT SOURCE -> DATA VALIDATION, REFINING, CLEANSING -> MAPPING -> DESTINATION The data refining, validation and mapping part of the process is mainly handled by a transformer stage. Transformer stage doesn't extract or write data to a target database. It handles extracted data, performs conversions, mappings, validations, passes values and controls the data flow. Transformer stages can have any number of input and output links. Input links can be primary or reference (used for lookups) and there can only be one primary input and any number of reference
Please refer to the examples below to find out what is the use of transformers.
In the job design depicted below there is a typical job flow implemented. The job is used for loading customers into the datawarehouse. The data is extracted from an ODBC data source, then filtered, validated and refined in the first transformer. Rejected (not validated) records are logged into a sequential file. The second transformer performs a lookup (into a country dictionary hash file) and does some other data mappings. The data is loaded into an Oracle database.
Design of a common datastage job with validations and mapping
It's a very common situation and a good practice to design datastage jobs in which data flow goes in the following way: EXTRACT SOURCE -> DATA VALIDATION, REFINING, CLEANSING -> MAPPING -> DESTINATION The data refining, validation and mapping part of the process is mainly handled by a transformer stage. Transformer stage doesn't extract or write data to a target database. It handles extracted data, performs conversions, mappings, validations, passes values and controls the data flow. Transformer stages can have any number of input and output links. Input links can be primary or reference (used for lookups) and there can only be one primary input and any number of reference
Please refer to the examples below to find out what is the use of transformers.
In the job design depicted below there is a typical job flow implemented. The job is used for loading customers into the datawarehouse. The data is extracted from an ODBC data source, then filtered, validated and refined in the first transformer. Rejected (not validated) records are logged into a sequential file. The second transformer performs a lookup (into a country dictionary hash file) and does some other data mappings. The data is loaded into an Oracle database.
Design of a common datastage job with validations and mapping
Designing jobs - sequential (text) files
Designing jobs - sequential (text) files
Sequential File stages are used to interract with text files which may involve extracting data from and write data to a text file. Sequential File stages can read files, create (overwrite) or append data to a text file. It can be processed on any drive that is local or mapped as a shared folder or even on an FTP server (combined with an FTP stage). Each Sequential File stage can have any number of inputs or outputs. However, trying to write to a sequential file simultaneously from two data streams will surely cause an error.
The use of sequential files in Datastage is pretty straightforward. Please refer to the examples below to find out how to use sequential files in datastage jobs.
Datastage sequential file properties
Sequential File stages are used to interract with text files which may involve extracting data from and write data to a text file. Sequential File stages can read files, create (overwrite) or append data to a text file. It can be processed on any drive that is local or mapped as a shared folder or even on an FTP server (combined with an FTP stage). Each Sequential File stage can have any number of inputs or outputs. However, trying to write to a sequential file simultaneously from two data streams will surely cause an error.
The use of sequential files in Datastage is pretty straightforward. Please refer to the examples below to find out how to use sequential files in datastage jobs.
Datastage sequential file properties
Designing jobs - ODBC and ORACLE stages
Designing jobs - ODBC and ORACLE stages
ODBC stages are used to allow Datastage to connect to any data source that represents the Open Database Connectivity API (ODBC) standard. ODBC stages are mainly used to extract or load the data. However, ODBC stage may also be very helpful when aggregating data and as a lookup stage (in that case it can play role of aggregator stage or a hash file and can be used instead). Each ODBC stage can have any number of inputs or outputs. The input links specify the data which is written to the database (they act as INSERT, UPDATE or DELETE statements in SQL). Input link data can be defined in various ways: using an SQL statement constructed by DataStage, a user-defined SQL query or a stored procedure. Output links specify the data that are extracted (correspond to the SQL SELECT statement). The data on an output link is passed through ODBC connector and processed by an underlying database. If a processing target is an Oracle database, it may be worth considering use of ORACLE (ORAOCI9) stage. It has a significantly better performance than ODBC stage and allows setting up more configuration options and parameters native to the Oracle database. There’s a very useful option to issue an SQL before or after main dataflow operations (Oracle stage properties -> Input -> SQL). For example, when loading a big chunk of data into an oracle table, it may increase performance to drop indexes in a ‘before SQL’ tab and create indexes and analyze table in a ‘after SQL’ tab ('ANALYZE TABLE xxx COMPUTE STATISTICS' SQL statement).
Update actions in Oracle stageThe destination table can be updated using various Update actions in Oracle stage. Be aware of the fact that it's crucial to select the key columns properly as it will determine which column will appear in the WHERE part of the SQL statement. Update actions available from the drop-down list:
Clear the table then insert rows - deletes the contents of the table (DELETE statement) and adds new rows (INSERT).
Truncate the table then insert rows - deletes the contents of the table (TRUNCATE statement) and adds new rows (INSERT).
Insert rows without clearing - only adds new rows (INSERT statement).
Delete existing rows only - deletes matched rows (issues only the DELETE statement).
Replace existing rows completely - deletes the existing rows (DELETE statement), then adds new rows (INSERT).
Update existing rows only - updates existing rows (UPDATE statement).
Update existing rows or insert new rows - updates existing data rows (UPDATE) or adds new rows (INSERT). An UPDATE is issued first and if succeeds the INSERT is ommited.
Insert new rows or update existing rows - adds new rows (INSERT) or updates existing rows (UPDATE). An INSERT is issued first and if succeeds the UPDATE is ommited.
User-defined SQL - the data is written using a user-defined SQL statement.
User-defined SQL file - the data is written using a user-defined SQL statement from a file.
ODBC stages are used to allow Datastage to connect to any data source that represents the Open Database Connectivity API (ODBC) standard. ODBC stages are mainly used to extract or load the data. However, ODBC stage may also be very helpful when aggregating data and as a lookup stage (in that case it can play role of aggregator stage or a hash file and can be used instead). Each ODBC stage can have any number of inputs or outputs. The input links specify the data which is written to the database (they act as INSERT, UPDATE or DELETE statements in SQL). Input link data can be defined in various ways: using an SQL statement constructed by DataStage, a user-defined SQL query or a stored procedure. Output links specify the data that are extracted (correspond to the SQL SELECT statement). The data on an output link is passed through ODBC connector and processed by an underlying database. If a processing target is an Oracle database, it may be worth considering use of ORACLE (ORAOCI9) stage. It has a significantly better performance than ODBC stage and allows setting up more configuration options and parameters native to the Oracle database. There’s a very useful option to issue an SQL before or after main dataflow operations (Oracle stage properties -> Input -> SQL). For example, when loading a big chunk of data into an oracle table, it may increase performance to drop indexes in a ‘before SQL’ tab and create indexes and analyze table in a ‘after SQL’ tab ('ANALYZE TABLE xxx COMPUTE STATISTICS' SQL statement).
Update actions in Oracle stageThe destination table can be updated using various Update actions in Oracle stage. Be aware of the fact that it's crucial to select the key columns properly as it will determine which column will appear in the WHERE part of the SQL statement. Update actions available from the drop-down list:
Clear the table then insert rows - deletes the contents of the table (DELETE statement) and adds new rows (INSERT).
Truncate the table then insert rows - deletes the contents of the table (TRUNCATE statement) and adds new rows (INSERT).
Insert rows without clearing - only adds new rows (INSERT statement).
Delete existing rows only - deletes matched rows (issues only the DELETE statement).
Replace existing rows completely - deletes the existing rows (DELETE statement), then adds new rows (INSERT).
Update existing rows only - updates existing rows (UPDATE statement).
Update existing rows or insert new rows - updates existing data rows (UPDATE) or adds new rows (INSERT). An UPDATE is issued first and if succeeds the INSERT is ommited.
Insert new rows or update existing rows - adds new rows (INSERT) or updates existing rows (UPDATE). An INSERT is issued first and if succeeds the UPDATE is ommited.
User-defined SQL - the data is written using a user-defined SQL statement.
User-defined SQL file - the data is written using a user-defined SQL statement from a file.
Designing jobs - datastage palette
Designing jobs - datastage palette
A list of all stages and activities used in the Datastage server edition is shown below.
Datastage server palette - general stages:
Datastage server palette - file stages:
Datastage server palette - database stages:
Datastage server palette - processing (transforming, filtering) stages:
Datastage server palette - sequence activities:
An overview of the stages palette in Datastage PX (Enterprise Edition): Datastage EE stages
Datastage-modules

The DataStage components:
Administrator - Administers DataStage projects, manages global settings and interacts with the system. Administrator is used to specify general server defaults, add and delete projects, set up project properties and provides a command interface to the datastage repository. With Datastage Administrator users can set job monitoring limits, user privileges, job scheduling options and parallel jobs default.
Manager - it's a main interface to the Datastage Repository, allows its browsing and editing. It displays tables and files layouts, routines, transforms and jobs defined in the project. It is mainly used to store and manage reusable metadata.
Designer - used to create DataStage jobs which are compiled into executable programs. is a graphical, user-friendly application which applies visual data flow method to develop job flows for extracting, cleansing, transforming, integrating and loading data. It’s a module mainly used by Datastage developers.
Director - manages running, validating, scheduling and monitoring DataStage jobs. It’s mainly used by operators and testers.

Datastage contents
Datastage tutorial & guide table of contents:
Lesson 1. Datastage-modules
Lesson 2. Designing jobs - datastage palette
Lesson 3. Extracting and loading data - ODBC and ORACLE stages
Lesson 4. Extracting and loading data - sequential files
Lesson 5. Transforming and filtering data
Lesson 6. Performing lookups in Datastage
Lesson 7. Implementing ETL process in Datastage
Lesson 8. SCD implementation in Datastage
Lesson 9. Datastage jobs real-life solutions
Lesson 10. Header - Items processing example
Lesson 1. Datastage-modules
Lesson 2. Designing jobs - datastage palette
Lesson 3. Extracting and loading data - ODBC and ORACLE stages
Lesson 4. Extracting and loading data - sequential files
Lesson 5. Transforming and filtering data
Lesson 6. Performing lookups in Datastage
Lesson 7. Implementing ETL process in Datastage
Lesson 8. SCD implementation in Datastage
Lesson 9. Datastage jobs real-life solutions
Lesson 10. Header - Items processing example
Datastage tutorial and training
Datastage tutorial and training
The tutorial is based on a Datastage 7.5.1 Server EditionDatastage tutorial TOC:
Lesson 1. Datastage-modules - the lesson contains an overview of the datastage components and modules with screenshots.
Lesson 2. Designing jobs - datastage palette - a list of all stages and activities used in Datastage
Lesson 3. Extracting and loading data - ODBC and ORACLE stages - description and use of the ODBC and ORACLE stages (ORAOCI9) used for data extraction and data load. Covers ODBC input and output links, Oracle update actions and best practices.
Lesson 4. Extracting and loading data - sequential files - description and use of the sequential files (flat files, text files, CSV files) in datastage.
Lesson 5. Transforming and filtering data - use of transformers to perform data conversions, mappings, validations and datarefining. Design examples of the most commonly used datastage jobs.
Lesson 6. Performing lookups in Datastage - how to use hash files and database stages as a lookup source.
Lesson 7. Implementing ETL process in Datastage - step by step guide on how to implement the ETL process efficiently in Datastage. Contains tips on how to design and run a set of jobs executed on a daily basis.
Lesson 8. SCD implementation in Datastage - the lesson illustrates how to implement SCD's (slowly changing dimensions) in Datastage, contains job designs, screenshots and sample data. All the Slowly Changing Dimensions types are described in separate articles below:
SCD Type 1
SCD Type 2
SCD Type 3 and 4
Lesson 9. Datastage jobs real-life solutions - a set of examples of job designs resolving real-life problems implemented in production datawarehouse environments in various companies.
Lesson 10. Header and trailer file processing - a sample Datastage job which processes a textfile organized in a header and trailer format.
DataStage-adv&disadv
Major business and technical advantages and disadvantages of using DataStage ETL tool
Business advantages of using DataStage as an ETL tool:
Significant ROI (return of investment) over hand-coding
Learning curve - quick development and reduced maintenance with GUI tool
Development Partnerships - easy integration with top market products interfaced with the datawarehouse, such as SAP, Cognos, Oracle, Teradata, SAS
Single vendor solution for bulk data transfer and complex transformations (DataStage versus DataStage TX)
Transparent and wide range of licensing options
Technical advantages of using DataStage tool to implement the ETL processes
Single interface to integrate heterogeneous applications
Flexible development environment - it enables developers to work in their desired style, reduces training needs and enhances reuse. ETL developers can follow data integrations quickly through a graphical work-as-you-think solution which comes by default with a wide range of extensible objects and functions
Team communication and documentation of the jobs is supported by data flows and transformations self-documenting engine in HTML format.
Ability to join data both at the source, and at the integration server and to apply any business rule from within a single interface without having to write any procedural code.
Common data infrastructure for data movement and data quality (metadata repository, parallel processing framework, development environment)
With Datastage Enterprise Edition users can use the parallel processing engine which provides unlimited performance and scalability. It helps get most out of hardware investment and resources.
The datastage server performs very well on both Windows and unix servers.
Major Datastage weaknesses and disadvantages
Big architectural differences in the Server and Enterprise edition which results in the fact that migration from server to enterprise edition may require vast time and resources effort.
There is no automated error handling and recovery mechanism - for example no way to automatically time out zombie jobs or kill locking processes. However, on the operator level, these errors can be easily resolved.
No Unix Datastage client - the Client software available only under Windows and there are different clients for different datastage versions. The good thing is that they still can be installed on the same windows pc and switched with the Multi-Client Manager program.
Might be expensive as a solution for a small or mid-sized company.
Business advantages of using DataStage as an ETL tool:
Significant ROI (return of investment) over hand-coding
Learning curve - quick development and reduced maintenance with GUI tool
Development Partnerships - easy integration with top market products interfaced with the datawarehouse, such as SAP, Cognos, Oracle, Teradata, SAS
Single vendor solution for bulk data transfer and complex transformations (DataStage versus DataStage TX)
Transparent and wide range of licensing options
Technical advantages of using DataStage tool to implement the ETL processes
Single interface to integrate heterogeneous applications
Flexible development environment - it enables developers to work in their desired style, reduces training needs and enhances reuse. ETL developers can follow data integrations quickly through a graphical work-as-you-think solution which comes by default with a wide range of extensible objects and functions
Team communication and documentation of the jobs is supported by data flows and transformations self-documenting engine in HTML format.
Ability to join data both at the source, and at the integration server and to apply any business rule from within a single interface without having to write any procedural code.
Common data infrastructure for data movement and data quality (metadata repository, parallel processing framework, development environment)
With Datastage Enterprise Edition users can use the parallel processing engine which provides unlimited performance and scalability. It helps get most out of hardware investment and resources.
The datastage server performs very well on both Windows and unix servers.
Major Datastage weaknesses and disadvantages
Big architectural differences in the Server and Enterprise edition which results in the fact that migration from server to enterprise edition may require vast time and resources effort.
There is no automated error handling and recovery mechanism - for example no way to automatically time out zombie jobs or kill locking processes. However, on the operator level, these errors can be easily resolved.
No Unix Datastage client - the Client software available only under Windows and there are different clients for different datastage versions. The good thing is that they still can be installed on the same windows pc and switched with the Multi-Client Manager program.
Might be expensive as a solution for a small or mid-sized company.
Friday, June 18, 2010
Tip4
- Firefox has an extension you can download to your browser that saves those pesky flv files too. Simply clicking tools, and downloader helper allows you to save them. Then you can use a Free program called Prism by NCH software to convert them to wma, avi,, asf, mpg, mp4, 3gp or mov files. Then you can email, burn or watch them over again in your favorite player. If you're a regular YouTube viewer, you've probably experienced the frustration of trying to save your favorite videos. The movies are presented in the Flash Video (FLV) format and can't be downloaded with a simple right-click. Flash Video makes highly-compressed streaming video possible, and many Web sites use it because it displays well in most browsers.One of the easiest ways to capture videos is with KeepVid a download-helper site. It's completely browser-based, so there's no software to download. After you've found a video you want to save, enter that video's URL at KeepVid, then select its originating site from a pop-up list. KeepVid works with a wide variety of video sites. You can reuse its sites list to discover new places to surf for videos.When you enter your video URLs, KeepVid prompts you to change the suffix of the downloaded file (so that instead of Video.htm, you download Video.flv). The only problem with the site is it leaves FLV files in their original format, so downloading alone isn't enough. To view your file, you'll need to either download a FLV viewer such as FLV Player, or convert your file into a more usable format (for conversion help, see Tip 2).Another good site for saving online video is YouTube Downloader, a simpler option that only works with YouTube. In this site, you enter the URL of the page with your chosen video and click "Get Download URL." You'll then create a URL for the video itself. Click that new link to download the video file. You shouldn't need to add a FLV suffix, but it's a possible fix if you have problems. Again, you'll either need to convert this file or download a FLV viewer to play it.
Youtube Download Tip3
Tip3
- Today I'm going to show you how to download videos from Youtube. On my desktop, I've a program called the YouTubeDownloader. This is a freely downloadable program, that's free to use and doesn't have, you don't have to register it or anything like that. It's a great program. So what we're going to do to use this program is we're going to open up our web browser, we're going to go to Youtube. Let's just do a quick search for a video. Let's find a video we would like to download. Let's say I like this video right here and I want to download to my computer. Just open it up in your web browser and then up here in the address bar, we need to click to where it highlights all of the address, right click on that and say copy. Now let's close Youtube and open up YouTubeDownloader. Very first thing it ask you for is a Youtube video URL. Just clear out what's in there, we're going to paste in what we had. Now what we have selected is to download the video from Youtube. Press okay. It's going to ask you where you want to save it, I'm just going to save it to my desktop. This is now going to the Youtube website and downloading that video from Youtube. Now the video is downloaded, we'll just click close on this dialog and change this to convert video that way we can watch it. Now we have our video selected, all we have to do is choose what we want to convert it to. You want to view it on a Windows Computer, WMV is a good file type, just with other options like Apple Quick Time or a video can be load on an Iphone, there's lots of different options here. I'm just going to select okay. It's going to ask you what quality video you want to create, medium's fine. And it is now building my video based upon that Youtube video.
Youtube Download Tip2
Tip2
- Download videos from YouTube by opening the Web browser, highlighting the address, and copying the file to the PC desktop. Convert downloaded YouTube videos to WMV files or Quick Time using tips from a software developer in this free video on general computer tips.
Youtube Download tips
Tip1
- You can download YouTube clips with a cursor pass and one click with RealPlayer. Pass the cursor over the current clip and a small pop up will appear above the clip asking if you wish to download the clip. It will be stored in your Realplayer download folder.
HomePage
HOME
Welcome to Tips and Tricks Blog!!
Please click the topic for Tips and Tricks:
Internet Download Manager
UTorrent
Metcafe
Subscribe to:
Comments (Atom)
